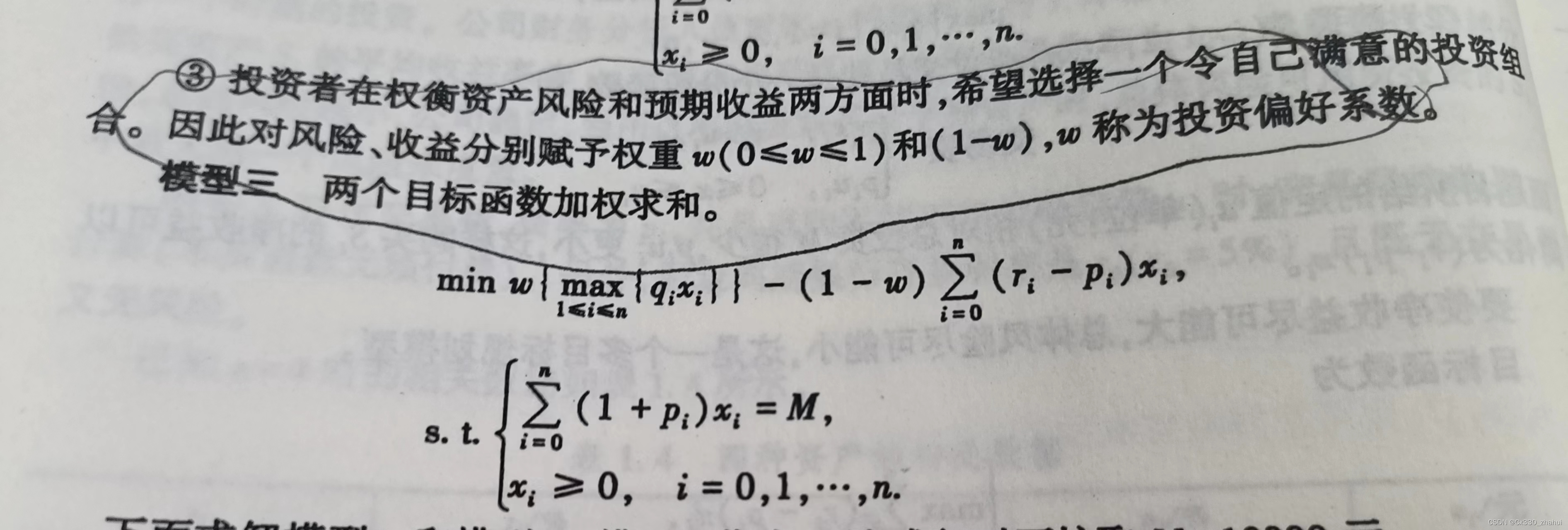1.原文名称
Auction-Based Ex-Post-Payment Incentive Mechanism Design for Horizontal Federated Learning with Reputation and Contribution Measurement
2.本文的贡献
- 我们提出了一种贡献度测量方法。
- 我们建立了一个声誉系统。声誉易于下降,难以提高。
- 结合声誉和拍卖,我们提出了一种根据表现选择工作者并支付报酬的机制。
- 我们证明了我们的机制满足诚实工作者的个体理性、预算可行性、真实性和计算效率。实验结果证明了其有效性。
3.相关的工作
Shapley Value (SV)被用来衡量工作者的贡献[Wei et al., 2020]。
SV可以通过组测试[Liu et al., 2021]或抽样[Wang et al., 2020b]来近似计算,但仍然需要很长时间。
本地模型的准确性间接或直接作为贡献[Nishio et al., 2020],但不能表达它们之间的相互影响。
模型参数的相似性或距离用于贡献度测量[Xu and Lyu, 2021],这可能会导致高质量工作者的声誉低。
张等人[2021b]利用贡献更新工作者的声誉。
康等人[2019]提出了一个主观逻辑模型,结合本地和推荐意见来计算声誉。赵等人[2020]设置了初始声誉。提交有用的模型时,声誉增加1,否则减少1。然而,声誉的粒度较大,缺乏区分度。
黎等人[2021]使用反向拍卖来帮助任务发布者选择工作者,以最大化社会福利。
曾等人[2020]提出了一个考虑资源差异的多方向拍卖机制。
黎等人[2020]采用了随机反向拍卖机制来最小化社会成本。
Sarikaya和Ercetin[2019]将工作者与发布者之间的交互建模为一个斯塔克伯格博弈,以激励和协调每个工作者。
康等人[2019]使用合同理论设计了一个激励机制。不同数据质量的工作者选择合同条款以最大化其效用。
4.系统模型和问题的定义
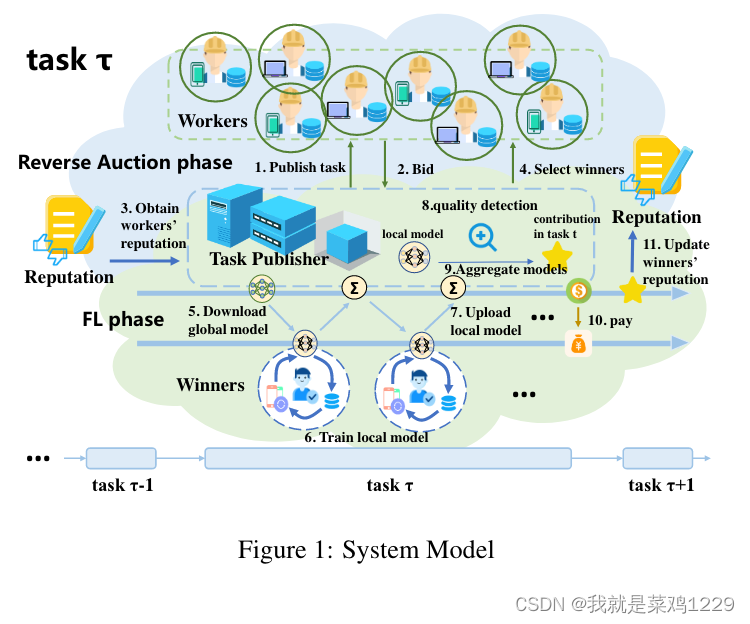
4.1 系统模型
一个联邦学习系统由一个任务发布者和大量的工作者组成。每个工作者的声誉
R
e
i
Re_i
Rei是公开的,但是数据质量、数量和自己的任务花费(成本)
c
i
c_i
ci是私有的。任务发布者有一个预算B,他自己的数据作为测试集和验证集。(如果他没有自己的数据呢?)
反向拍卖
- 发布者进行任务的发布
- 工作者i提交密封的竞标价格 b i b_i bi
- 发布者获得每个工作者的累计声誉
- 结合出价选择工作者。
- 下载全局模型
- 利用本地数据进行训练
- 上传本地模型
- 衡量质量(重点)
- 聚合模型
- 支付费用
- 更新信誉
4.2 问题定义
设置一个激励机制 M ( f , p ) \mathbb M(f,p) M(f,p),包含一个挑选机制和支付机制。
- 用户的集合为 S S S
- 每个工人的贡献
u
i
u_i
ui定义为
u i = { 0 , 如果 i ∉ S p i − c i , 如果 i ∈ S u_i = \begin{cases} 0, & \text{如果 } i \notin S \\ p_i - c_i, & \text{如果 } i \in S \end{cases} ui={0,pi−ci,如果 i∈/S如果 i∈S - 总预算为 B B B
- 同时需要满足 ∑ i ∈ S p i ≤ B \sum_{i\in S}p_i \le B ∑i∈Spi≤B
- 用累计的声誉间接反映数据的质量,发布者的效用建模为 U = ∑ i ∈ S R e i U = \sum_{i\in S}Re_i U=∑i∈SRei
- 机制的目标是通过确定获胜工作者集合S来最大化U
需要满足的四个经济属性
诚实工作者的个体理性:诚实工作者的效用非负。
预算可行性:总支付不能超过预算。
计算效率:机制的时间复杂度是多项式的。
真实性:报告真实成本可以最大化工作者的效用。
4.3 如何衡量贡献
一种直观的衡量贡献的方法是评估本地模型在验证集上的性能,例如准确率和损失。直接使用准确率作为工作者贡献的方法等同于将相同的权重分配给每个验证样本,但这是不公平的,因为每个样本的预测难度是不同的。更难以预测的样本应该被赋予更大的权重,并且工作者的贡献取决于他们在加权样本上的表现。
本文的贡献度衡量分为两步:
- 首先,确定每个样本的权重,然后评估工作者在加权样本上的表现。验证样本的权重由所有工作者的预测能力决定,预测能力由预测结果为真实标签的概率决定。
- U为工作者集,i是U中的一个工作者
- D是验证集,j是D中的一个样本
- i正确预测样本j的概率定义为 P i , j P_{i,j} Pi,j
- 样本j的权重为: w j = ∑ i ∈ U − ln P i , j ∑ i ∈ U ∑ j ∈ D − ln P i , j w_j = \frac{\sum_{i\in U} -\ln P_{i,j}}{\sum_{i\in U}\sum_{j\in D} -\ln P_{i,j}} wj=∑i∈U∑j∈D−lnPi,j∑i∈U−lnPi,j
- 根据每个人对每个样本预测的准确率和样本的权重可以计算出每个人的贡献
- c o n t r i b i = ∑ j ∈ D P i , j w j contrib_i = \sum_{j\in D} P_{i,j} w_j contribi=∑j∈DPi,jwj
。以上是工作者i在一个全局轮次中的贡献。将工作者i在轮次t中的贡献表示为 c o n t r i b i t contrib^t_i contribit,并通过 c o n t r i b i t = c o n t r i b t i max k ∈ U ( c o n t r i b k t ) contrib^t_i= \frac{contrib_t i}{\max_{k\in U} (contrib^t_k)} contribit=maxk∈U(contribkt)contribti进行标准化。
工作者i对任务的贡献 c o n t r i b i contrib_i contribi由 c o n t r i b i = ∑ t ∈ T c o n t r i b i t ∣ T ∣ contrib_i = \sum_{t\in T} \frac{contrib^t_i}{|T|} contribi=∑t∈T∣T∣contribit计算,其中T是工作者i参与的所有全局轮次。
4.4 声誉建模
声誉是对工作者质量和可靠性的评价,使发布者能够选择高质量的工作者。
内部声誉:在特定任务中的声誉建模为内部声誉
累计声誉:将所有历史任务中的声誉整合为累积声誉
内部声誉代表了工作者在当前任务中的表现,这与他的贡献和本地模型的质量检测相关。
使用张等人[2021a]提出的方法来检查本地模型的质量。当工作者i参与模型聚合和不参与时,全局模型在验证集上的损失分别为
l
l
l和
l
−
i
l_{−i}
l−i。
设定预定义阈值δ = −0.005,如果
∆
l
i
=
l
−
i
−
l
≥
δ
∆l_i = l−i − l ≥ δ
∆li=l−i−l≥δ,则工作者i通过检测,只有通过的本地模型才能参与模型聚合。
为了建模内部声誉,我们引入了工作者i的可信度
t
r
u
s
t
i
trust_i
trusti,它表示其本地模型的接受程度。
t
r
u
s
t
i
trust_i
trusti是Gompertz函数的输出,其输入如下所示:
x i = θ ⋅ n i p a s s − ( 1 − θ ) ⋅ n i f a i l θ ⋅ n i p a s s + ( 1 − θ ) ⋅ n i f a i l x_i = \frac{\theta \cdot n_i^{pass} - (1-\theta) \cdot n_i^{fail} }{\theta \cdot n_i^{pass} + (1-\theta) \cdot n_i^{fail} } xi=θ⋅nipass+(1−θ)⋅nifailθ⋅nipass−(1−θ)⋅nifail
n pass i n_{\text{pass}_i} npassi和 n fail i n_{\text{fail}_i} nfaili分别是工作者i通过和未通过检测的次数, θ ∈ ( 0 , 0.5 ) \theta \in (0, 0.5) θ∈(0,0.5)是预定义参数,表示更多的关注点放在未通过检测上。我们设置 θ = 0.4 \theta = 0.4 θ=0.4。
Gompertz函数是一种增长曲线,适用于建模个体交互的信任[Zhang et al., 2021a]。Gompertz函数描述为y = a exp(b exp(c · x)),其中a、b和c是参数,x是输入,y是输出。我们设置a = 1,b = −1,c = −5.5。工作者i的信任度为 t r u s t i = e x p ( − e x p ( − 5.5 x i ) ) trust_i = exp(− exp(−5.5xi)) trusti=exp(−exp(−5.5xi))
然后,将工作者i在任务τ中的贡献contribi ∈ [0, 1]和信任度trusti ∈ [0, 1]结合起来,得到他的内部声誉 r e i τ re^τ_i reiτ ∈ [0, 1]。在不引起混淆的情况下省略标记τ,因此 r e i = c o n t r i b i ⋅ t r u s t i re_i = contribi · trust_i rei=contribi⋅trusti
工作者i的累积声誉Reτ i 来自于所有历史任务的内部声誉。内部声誉越新,越能反映工作者的本质。因此,使用移动平均法来建模工作者i的累积声誉,如下所示:
R
e
i
τ
=
α
⋅
r
e
i
τ
+
(
1
−
α
)
⋅
R
e
i
τ
−
1
Re^{\tau}_i = \alpha \cdot re^{\tau}_i + (1 - \alpha) \cdot Re^{\tau-1}_i
Reiτ=α⋅reiτ+(1−α)⋅Reiτ−1
α是衰减系数(该值是动态更新的,这里就不细说了,感觉不是重点),是最新内部声誉的权重。当工作者连续表现良好时,其累积声誉应该逐渐轻微增加。一旦执行了糟糕的任务,其累积声誉应立即大幅下降。因此,我们考虑连续良好和糟糕任务的数量以及最新内部声誉作为动态确定衰减系数α的因素。
4.5 工作者的挑选和支付
现有的基于拍卖的研究确定了工作者在任务之前的最终报酬。由于报酬与实际表现无关,工作者可能不按照所声明的计划工作,这将影响全局模型。为解决上述挑战,我们设计了一个基于声誉和比例分配的逆向拍卖的事后支付激励机制 M(f , p)。我们的选择机制 f 与比例分配机制一致,而我们的支付机制 p 在此基础上进行了改进,以便根据工作者的表现确定奖励。这就是所谓的事后支付。
出版商需要选择更多高质量的工作者以获得高精度模型。
- 为了选择更多的工作者,出版商倾向于选择报价较低的工作者。
- 为了选择更高质量的工作者,他倾向于选择累积声誉较高的工作者。
平衡报价和累积声誉,我们将工作者的单位累积声誉报价定义为他的成本密度 ρ i = b i R e i ρ_i=\frac{b_i}{Re_i} ρi=Reibi,我们按照非递减(从小到大,小的性价比高)顺序进排序。需要满足 ρ k ≤ B / ( R e k + ∑ i = 1 k − 1 R e i ) ρ_k \le B/(Re_k+\sum^{k-1}_{i=1}Re_i) ρk≤B/(Rek+∑i=1k−1Rei)
序列中的前 𝑘 个工作者形成了获胜的工作者集 𝑆。为了确定奖励,我们定义支付密度阈值 ρ ∗ = m i n ( B ∑ i ∈ S R e i , b k + 1 R e k + 1 ) ρ^*=min(\frac{B}{\sum_{i\in S}Re_i},\frac{b_{k+1}}{Re_{k+1}}) ρ∗=min(∑i∈SReiB,Rek+1bk+1)
失败的工作者获得0报酬。获胜的工作者具有奖励上限,以确保真实性和预算可行性。获胜的工作者 𝑖∈𝑆 的奖励上限为 p u p i = R e i ⋅ ρ ∗ p_{up_i}=Re_i \cdot ρ^* pupi=Rei⋅ρ∗
任务完成后,评估每个获胜工作者 𝑖 的内部声誉
r
e
i
re_i
rei ,并且他的临时奖励为
p
i
′
=
r
e
i
⋅
m
a
x
(
B
∑
j
∈
S
r
e
j
)
p_i^\prime = re_i \cdot max(\frac{B}{\sum_{j\in S}re_j})
pi′=rei⋅max(∑j∈SrejB)。
最终的奖励为:
p
i
=
m
i
n
(
p
u
p
i
,
p
i
′
)
p_i=min(p_{up_i},p_i^\prime)
pi=min(pupi,pi′)。
4.6 跳过理论验证
5. 实验
使用MNIST数据集和全连接模型以及FashionMNIST数据集和LeNet模型进行实验。发布者有一个大小为5000的验证集和一个测试集,每个工作者都有一个大小为1000的训练集,随机从相应的数据集中抽样而来。通过将标签修改为另一个标签,每个工作者的数据准确性可能会有所不同。获胜的工作者将使用学习率为0.05和批量大小为128的设置对本地模型进行1个周期的训练。
- 我们使用等权重样本方法作为基准,它与我们的加权样本方法相同,但样本的权重相等。
- 第一种情况是,10个工作者的数据是独立相似分布的,其准确性从1.0逐渐降低到0.1。
- 第二种情况是,10个工作者的数据是非独立相似分布的,准确性为1.0,其中工作者0具有所有标签的数据,而其他工作者缺少某个标签的数据。
图2显示了Case 1的结果,贡献随着数据精度的降低而降低。但局部模型的精度相差不大,不能反映数据质量。
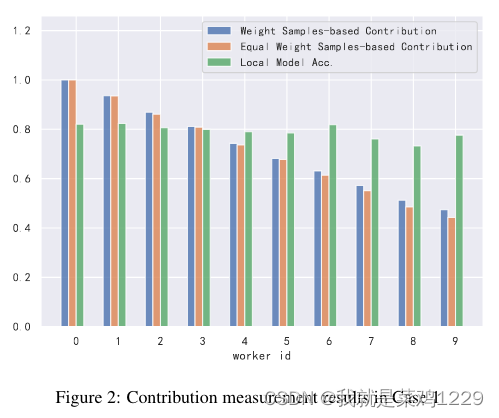
图3显示了案例2的结果,与基准和局部模型精度相比,我们的方法可以突出更高质量的工作者0的贡献。这些结果表明,我们的方法可以有效和公平地度量贡献
6.个人总结
- 提出了贡献衡量的新定义,赋予每个样本不一样的权重。
- 建立了声誉机制和拍卖体系


![【阿里笔试题汇总】[全网首发] 2024-04-29-阿里国际春招笔试题-三语言题解(CPP/Python/Java)](https://img-blog.csdnimg.cn/direct/274440ba75ee462aa6a003a129bbcefd.png#pic_center)